More SOTU Scaling
Will Lowe (2014-01-30 21:16)
A couple of days ago the Monkey Cage featured Ben Lauderdale’s one-dimensional scaling model of US State of the Union addresses. In this post, I replicate the analysis with a closely related model, ask what the scaled dimension actually means, and consider what things would look like if we added another one.
The technical details are all at the bottom of the post if you want to try this at home.
Replication
First the replication materials. Historical State of the Union addresses are available in machine readable form from the American Presidency Project. Like Ben, I’m only going to go back to 29 years to 1986. From these addresses I construct a cross-tabulation of words and the Addresses they were used in, trim it a bit, and scale it using correspondence analysis (CA).
If you’ve listened to almost any talk I’ve given in the last two years (or maybe read this) you’ll know that CA is, among other things, a least-squares approximation to the text scaling model known to political scientists as Wordfish. Ben fitted a ‘variant of Wordfish’ so we should expect very much the same results here. And we get them:
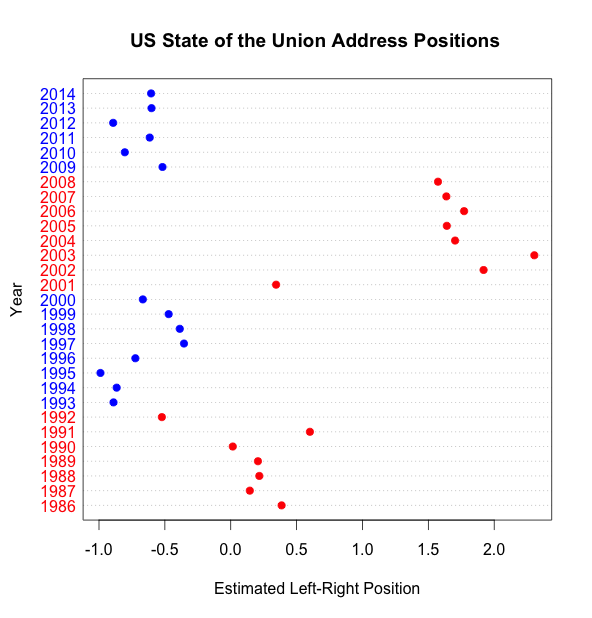
I haven’t bothered to bootstrap any confidence intervals around these positions, but you can see that the Address positions match the original analysis very closely.
Dimensionality
CA models are cheap to fit and we’ve just seen that they recover what a more intensive Wordfishing approach would give us, so let’s go a bit further and ask what would happen if we fitted a model with more than one dimension. For identification reasons CA requires that the second dimension be orthogonal to the first, so it’s sufficient to show how the Addresses would line up in this second dimension:
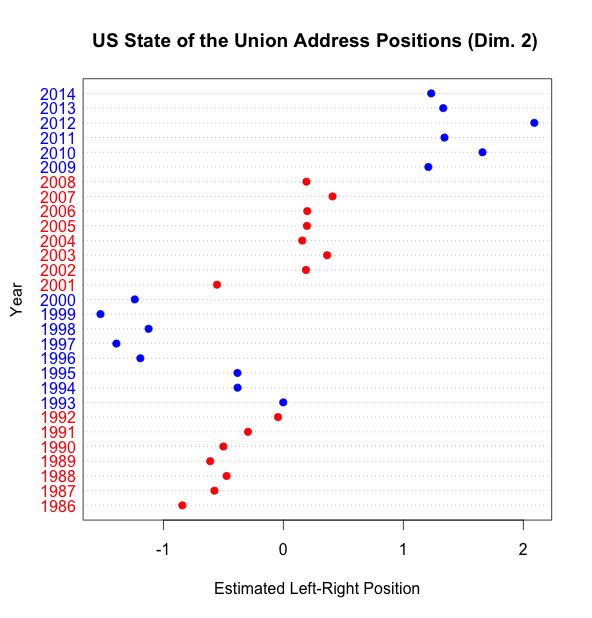
and just for completeness, here they are plotted together:
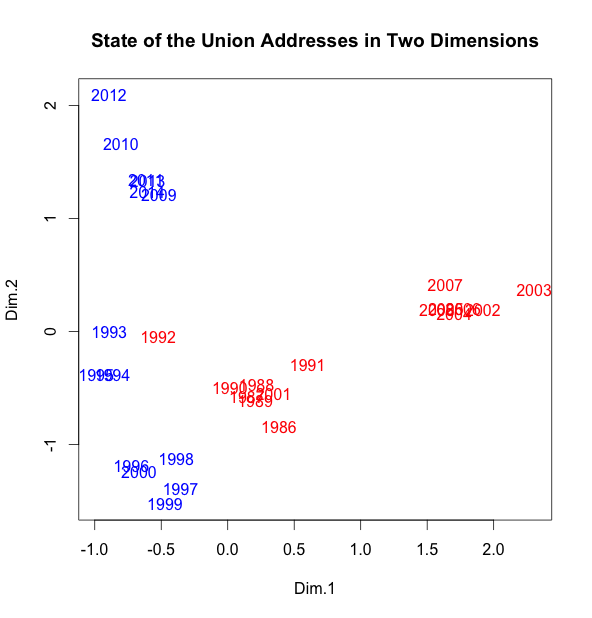
It seems that the most recent Bush presidency is quite distinctive, rhetorically speaking.
Distinctive vocabulary
What are the words that distinguish those eight years from the last three decades of Addresses? Well, of the top 20 word stems that push an Address to the right in the original plot, 14 are
cheney, attack, terrorist, septemb, oppress, compass, iraqi,
terror, danger, liabil, coalit, lawsuit, enemi, iraq
so that pretty much nails down the substance of the primary dimension in the original analysis.
The second dimension is a more diffuse. Among the top 20 words stems in this dimension are
energi, solar, children, entrepreneur, profit, job,
busi, parent, manufactur, fact, consum,
We get a slightly better view by plotting the top 100 words in both dimensions
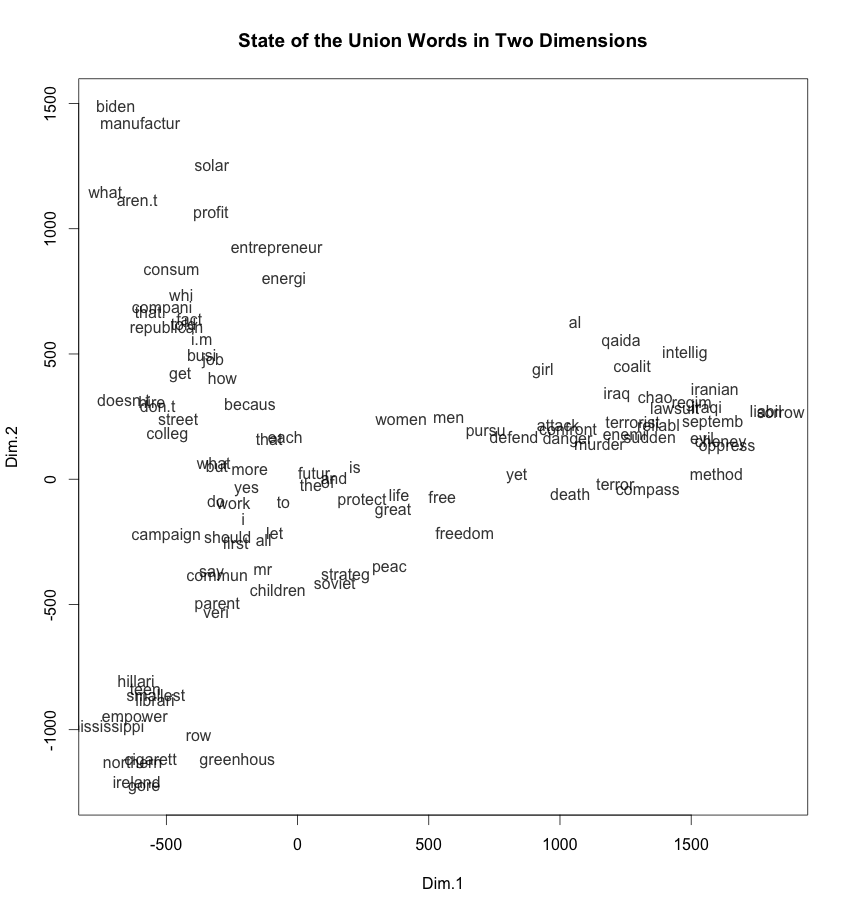
These scaling models give us a first rhetorical dimension that is essentially about military action and second that represents the economic basis of ordinary politics. Or, as Rammstein put it rather more pithily:
“Coca cola, sometimes war”
Technicalities
Each address at the American Presidency Project gets its own web page
so it is the work of a moment to curl the ones we want onto a local
disk. In each web page the president’s words are wrapped in a span of
class "displaytext", so we can pull them out using some XPath and
collapse all the paragraphs together, because text scaling methods
ignore all that sort of thing anyway.
Here are the relevant lines of R if you want to do it yourself.
require(XML)
## parse the web page
doc <- htmlTreeParse(filename,
useInternalNodes = TRUE)
## extract just the speech bits using xpath
block <- getNodeSet(doc,
"//span[@class='displaytext']/descendant::text()")
## merge all the paragraphs together
txt <- paste(lapply(block, xmlValue),
collapse = " ")
## remove references to applause
txt <- gsub(pattern="\\[ applause \\]",
replacement = "",
x = txt)
I constructed the word count matrix from these documents by saving them each to a file and pouring them into JFreq.
After reading it back into R, I trimmed it by removing words that
occurred less than 5 times or in less than 5 documents using the
‘trim’ function of the
austin R package. The
correspondence analysis used Greenacre and Nenadic’s R package
ca. If you try
this at home, make the plots with words from the margins of the
original word count matrix margin; the {ca} package inexplicably removes
all the vowels.
The ‘most distinctive words’ are defined as those with a ‘quality’ over 500 (out of 1000) and ordered according to their correlation (think factor analysis loadings) with each dimension. These summary statistics are computed by the package and Greenacre 2007 has more details on their interpretation.

