Quantifying the international search for meaning
Will Lowe (2013-02-09 23:11)
Inspired by Preis et al.’s article Quantifying the advantage of looking forward, recently published in Scientific Reports (one of Nature publishing group’s journals), I wondered if similar big-data web-based research methods might address a question even bigger than how much different countries wonder about next year. How about the meaning of life. Who is searching for clarification about the meaning of life? And how is that related to the more obvious life task of getting richer?
The article’s authors found that the more that countries thought about the next year than the previous one, the richer they got. Or at least that’s what their graph seemed to say to me, and correlation coefficients between 0.53 and 0.78 pretty much settled it.
To investigate this relationship for my own question, I needed a solid operationalisation of the relevant variables. Now, the meaning of life is 42. That part was easy. But how to quantify the extent to which people in different countries are looking for clarity about what this really means to them?
When they don’t know something, many people and perhaps all my students try a google search. Perfect. So following the original article’s methodology, I used last year’s volume of Google searches for ‘42’ as a cool big-data measure of the international quest for meaning. And just like the authors, I downloaded these search volumes for 2012 and saved them to a file. The CIA World Factbook collects GDP per capita data, so I downloaded that too.
Let’s have a look at the data. Here’s my version of the authors’ Figure 1B. Like them, I’ve labeled all the interesting countries, although not with little flags because I don’t want to make you look them up like I had to.
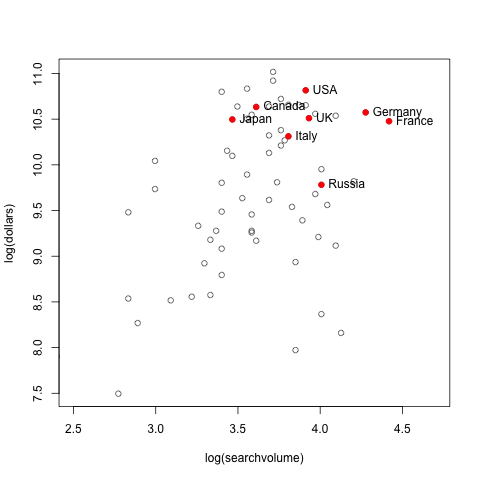
Looks like a relationship. The correlation is 0.47 (df=91, p<.0001). Solid and significant.
But I was not content with the admittedly fierce complexities of bivariate correlation analysis. No. I wanted a scale free measure of the sensitivity of GDP to the changes in the amount of meaningful searching that was going on. I wanted an elasticity.
This got a little bit complicated. If you’re reading this at a standing desk you may wish to sit down while I explain.
Call the volume of searches for meaning in life SML.The elasticity of GDP with respect to SML is the coefficient in a regression of log GDP on log SML.
That elasticity is 0.95 (t=3.817 p < 0.001). Still solid. Still significant. That’s the power of causation for you. A 10% increase in searching for the meaning of life in a country generates a 9.5% increase in GDP. So, get searching folks. Your country needs you.
Here’s the code:
## internet users for each country from CIA WFB
intusers <- read.csv("intusers.tsv", sep='\t', header=FALSE)
intusers$users <- apply(intusers, 1, function(x){ as.numeric(gsub(",", '',
substring(x[3], 2))) })
names(intusers) <- c("id", "country", "int-users", "users")
## GDP per capita for each country from CIA WFB
gdp <- read.csv("gdpcia.tsv", sep='\t')
gdp$dollars <- apply(gdp, 1,
function(x){ as.numeric(gsub(",", '', substring(x[3], 2))) })
names(gdp) <- c('id', 'country', 'gdp-per-capita', 'dollars')
## volume of searches for 42 in 2012 for each country
f42 <- read.csv("searchvol42.tsv", sep='\t')
together <- merge(f42, gdp, by="country")
## run the correlation test
together2 <- merge(together, intusers, by="country")
with(together2[together2$users>2000000,],
cor.test(log(dollars), log(searchvolume)))
## make the plot
with(together2[together2$users>2000000,],
plot(log(searchvolume), log(dollars), col=rgb(.4,.4,.4), xlim=c(2.5,4.7)))
of.interest <- c("United Kingdom", "United States", "Canada", "Russia",
"Japan", "Germany", "France", "Italy")
labs <- together2[together2$country %in% of.interest,]
cnames <- labs$country
cnames <- sub("United Kingdom", "UK", cnames)
cnames <- sub("United States", "USA", cnames)
labs$country <- cnames
points(log(labs$searchvolume), log(labs$dollars), pch=19, col='red')
text(log(labs$searchvolume), log(labs$dollars), labs$country, pos=4)
## run the regression
with(together2[together2$users>2000000,],
summary(lm(log(dollars) ~ log(searchvolume)))

