Yoshikoder
The Yoshikoder is a cross-platform multilingual content analysis program developed as part of the Identity Project at Harvard‘s Weatherhead Center for International Affairs.
You can load documents, construct and apply content analysis dictionaries, examine keywords-in-context, and perform basic content analyses, in any language. About two laptops ago it looked like this:
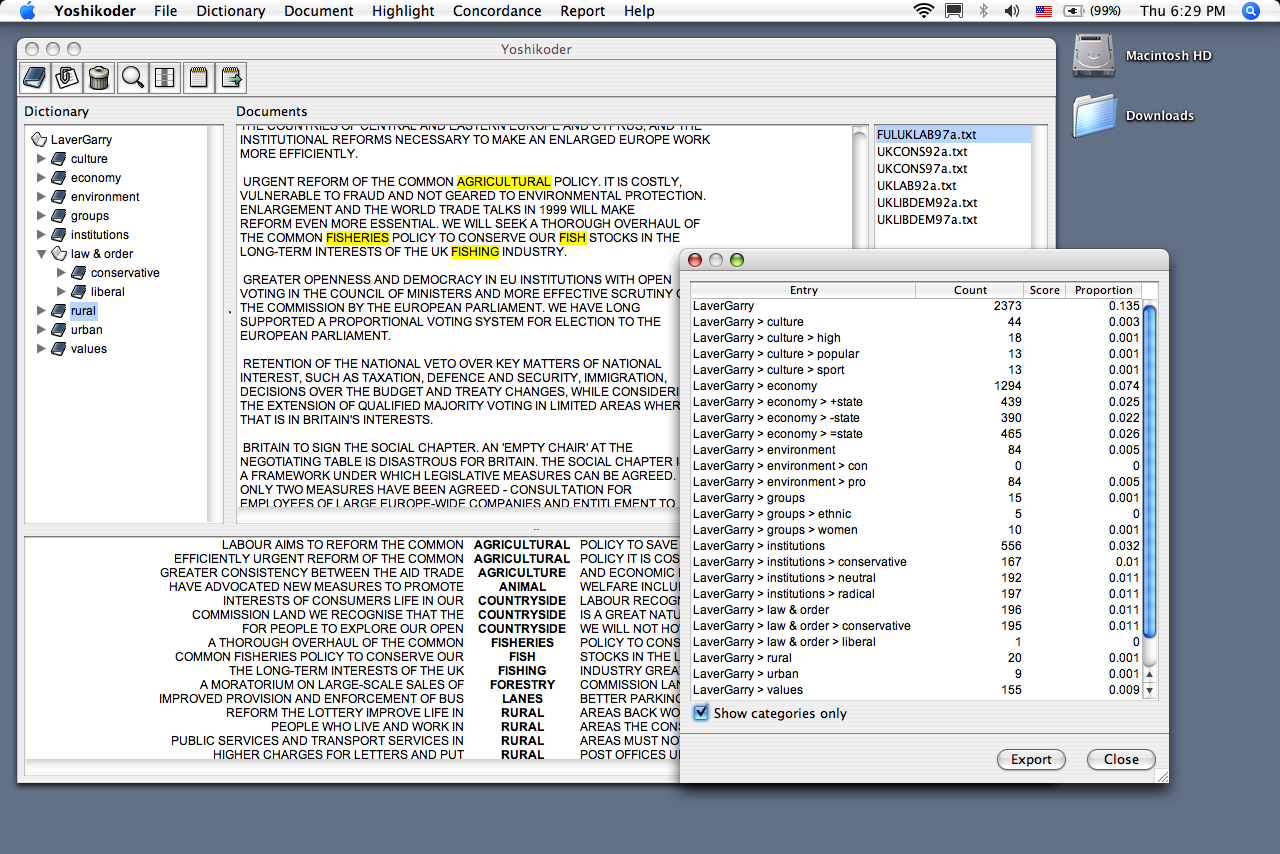
The Yoshikoder works with text documents, whether in plain ASCII, Unicode (e.g. UTF-8), or national encodings (e.g. Big5 Chinese.) You can construct, view, and save keywords-in-context. You can write content analysis dictionaries. Yoshikoder provides summaries of documents, either as word frequency tables or according to a content analysis dictionary. You can also apply a dictionary analysis to the results of a concordance, which provides a flexible way to study local word contexts. Yoshikoder’s native file format is XML, so dictionaries and keyword-in-context files are non-proprietary and human readable.
Some downloadable dictionaries and other content analysis resources can be found at the old place.
Download
You can download Version 0.6.5.
The source code is an uncharacteristic mess, mostly because I learnt Java while writing it.
License
Yoshikoder is open source software distributed under the Gnu Public License (GPL).
Citation
If you’d like to refer to the package in written work, you can use this:
Lowe W. (2015) ‘Yoshikoder: Cross-platform multilingual content analysis’. Java software version 0.6.5, URL: https://yoshikoder.org
If you found that useful…
